For there to be a correspondence between the information of the polynucleotide and that of the polypeptide, there is a code: the genetic code.
The general characteristics of the genetic code can be listed as follows:
The genetic code is made up of triplets, and is devoid of internal punctuation (Crick & Brenner,).
It "was deciphered through the use of" open cell translation systems "(Nirenberg & Matthaei, 1961; Nirenberg & Leder, 1964; Korana, 1964).
It is highly degenerate (synonyms).
The organization of the code table is not accidental.
Triplets "nonsense".
The genetic code is "standard", but not "universal".
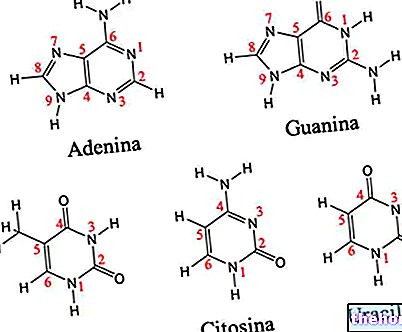
Looking at the table of the genetic code it must be remembered that it refers to the translation of the "RNAm to polypeptide, for which the nucleotide bases involved are A, U, G, C. The biosynthesis of a polypeptide chain is the translation of the nucleotide sequence in sequence amino acid.

Each base triplet of the RNAm, called codon, has the first base in the left column, the second in the top row, the third in the right column. Let's take for example tryptophan (i.e. Try) and we see that the corresponding codon will be , in order, UGG. In fact, the first base, U, includes the entire row of boxes at the top; in this, G identifies the rightmost box and the fourth line of the box itself, where we find written Try. Similarly, to synthesize the tetrapeptide Leucine-Alanine-Arginine-Serína (symbols Leu-Ala-Arg-Ser) we can find in the code the UUA-AUC-AGA-UCA codons.

At this point, however, it should be noted that all the amino acids of our tetrapeptide are encoded (unlike tryptophan) by more than one codon. It is no coincidence that in the example just reported we have chosen the indicated codons. We could have encoded the same tripeptide with a different RNAm sequence, such as CUC-GCC-CGG-UCC.
Initially, the fact that a single amino acid corresponded to more than a triplet was given a meaning of randomness, also expressed in the choice of the term of degeneration of the code, used to define the phenomenon of synonymy. On the other hand, some data suggest that the availability of synonyms referable to different stability of the genetic information is not at all accidental. This seems to be confirmed also by the finding of a different value of the A + T / G + C ratio in the different stages of evolution. For example, in prokaryotes, where the need for variability is not satisfied by the rules of Mendelism and neo-Mendelism, the A + T / G + C ratio tends to increase. The consequent lower stability, in the face of mutations, provides greater opportunities for variability random from gene mutation.
In eukaryotes, in particular in multicellular cells, in which it is necessary that the cells of the single organism all keep the same hereditary patrimony, the A + T / G + C ratio in DNA tends to decrease, decreasing the opportunity for somatic gene mutations.
The existence of synonymous codons in the genetic code raises the problem, already mentioned, of the multiplicity or not of anticodons in the RNAt.
It is certain that there is at least one RNAt for each amino acid, but it is not equally certain whether a single RNAt can bind to a single codon, or can recognize synonyms indifferently (especially when these differ only for the third base).
We can conclude that there are on average three synonymous codons for each amino acid, while anticodons are at least one, and no more than three.
Recalling that genes are intended as single stretches of very long polynucleotide sequences of DNA, it is clear that the beginning and the end of the single gene must necessarily be contained in the memory.
BIOSYNTHESIS OF PROTEINS
In different parts of the DNA there is the opening of the double chain and the synthesis of the different types of RNA.
During the loading step, the RNAt bind to the amino acids (previously activated by the ATP and by the specific enzyme). The biosynthetic "machinery" is unable to "correct" incorrectly loaded tRNAs.
The RNAr then splits into the two subunits and, by binding to the ribosomal proteins, gives rise to the assembly of the ribosomes.
The RNAm, passing through the cytoplasm, binds to the ribosomes, forming the polysome. Each ribosome, flowing on the messenger, gradually hosts the RNAt complementary to the relative codons, taking the amino acids and binding them to the polypeptide chain in formation.
The relatively stable RNAt re-enter the circulation. The ribosomes are also used again, releasing the already assembled polypeptide.
The messenger, less stable because it is all monocatenary, is cleaved (by the ribonuclease) into the constituent ribonucleotides.
The cycle thus continues, synthesizing one after the other the polypeptides on the messenger RNAs supplied by the transcription.